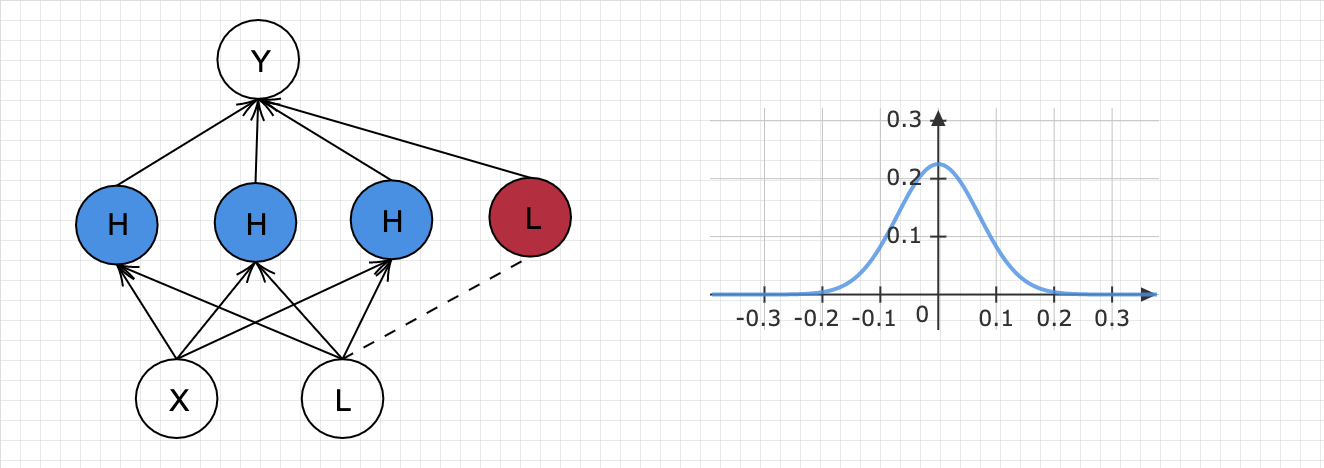
Variational inference for Bayes Network
In general neural networks have a sort of loss like that:
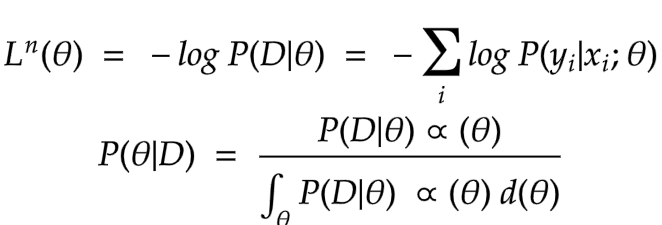
However, The part of the denominator integral is intractable of finding an analytic solution solution in practice. Therefore, we are going to make a distribution approaching the original distribution. KL divergence can be used to indicate the difference between these two distributions.
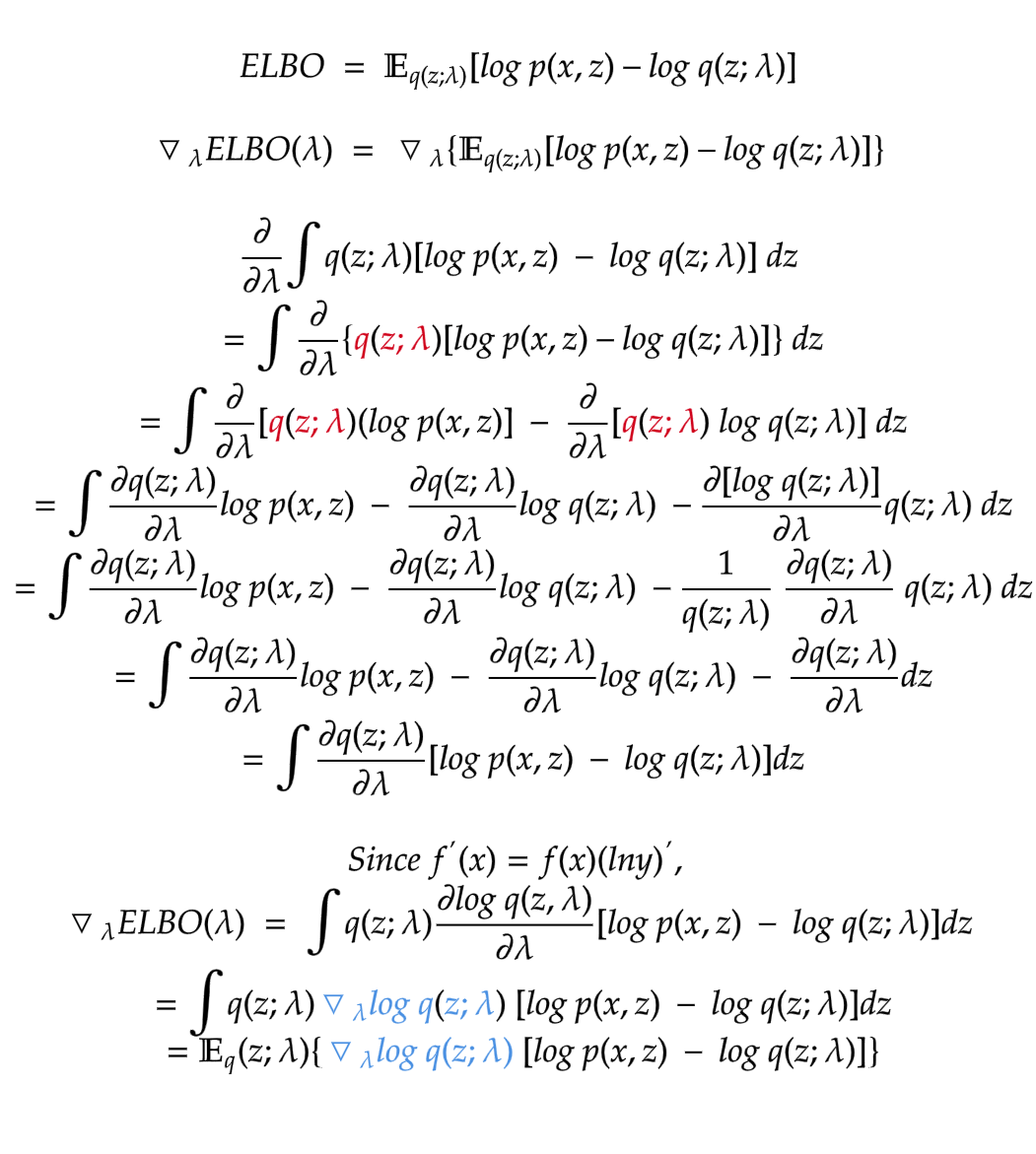
Enjoy Reading This Article?
Here are some more articles you might like to read next: