Publications
For the recent publications, please go to my Google Scholar directly.
Preprints
- Preprint
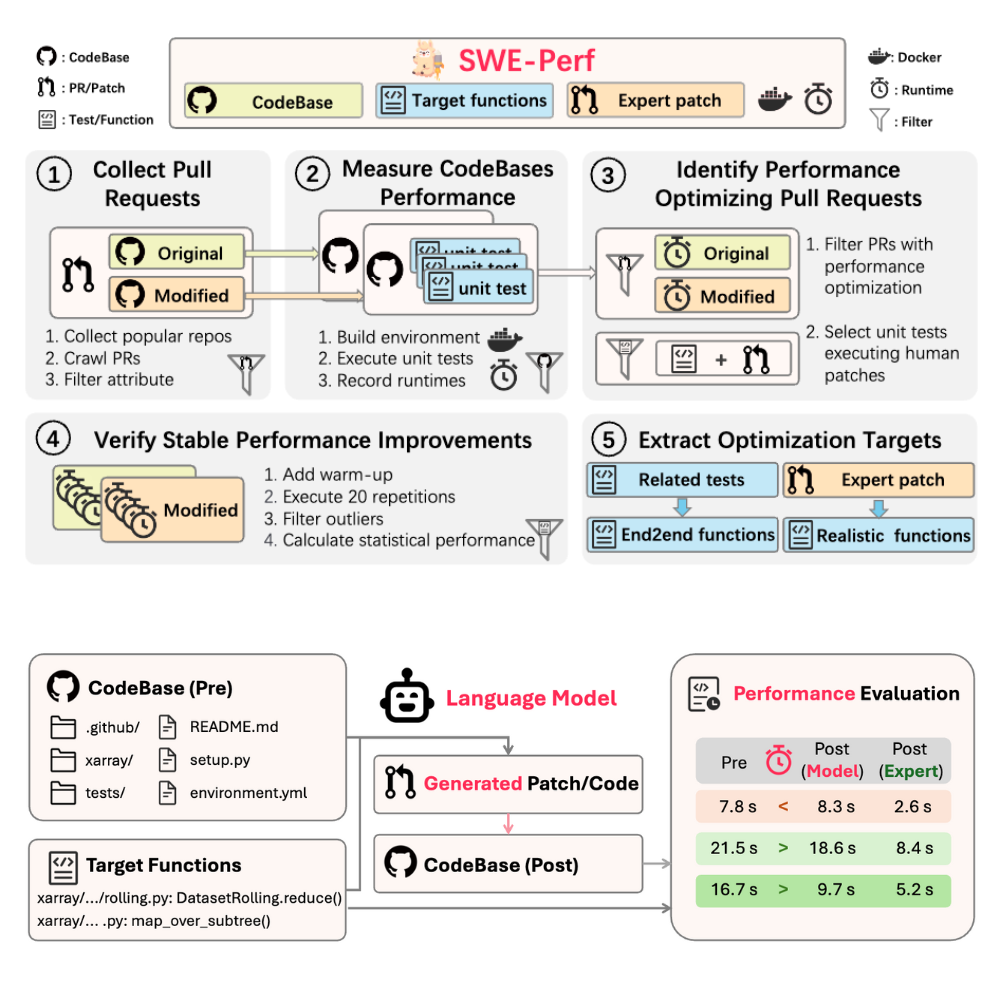 SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?arXiv preprint arXiv:2507.12415, 2025
SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?arXiv preprint arXiv:2507.12415, 2025 - Preprint
 Nexus: Execution-Grounded Multi-Agent Test Oracle SynthesisarXiv preprint, 2025
Nexus: Execution-Grounded Multi-Agent Test Oracle SynthesisarXiv preprint, 2025 - Preprint
 Secure Code Generation via Online Reinforcement Learning with Vulnerability Reward ModelarXiv preprint, 2025
Secure Code Generation via Online Reinforcement Learning with Vulnerability Reward ModelarXiv preprint, 2025 - Preprint
 Scaling Code LLM Training and Test-Time Inference via Execution-Free Reward ModelsarXiv preprint, 2025
Scaling Code LLM Training and Test-Time Inference via Execution-Free Reward ModelsarXiv preprint, 2025 - Preprint
 Paper Espresso: From Paper Overload to Research InsightarXiv preprint, 2025
Paper Espresso: From Paper Overload to Research InsightarXiv preprint, 2025





Published Papers
- ICLR
 Beyond Prompt-Induced Lies: Investigating LLM Deception on Benign PromptsInternational Conference on Learning Representations, 2026
Beyond Prompt-Induced Lies: Investigating LLM Deception on Benign PromptsInternational Conference on Learning Representations, 2026 - TOSEM
 Benchmarking LLMs for Unit Test Generation from Real-World FunctionsACM Transactions on Software Engineering and Methodology, 2026
Benchmarking LLMs for Unit Test Generation from Real-World FunctionsACM Transactions on Software Engineering and Methodology, 2026 - ACL
 Semantics-Aligned, Curriculum-Driven, and Reasoning-Enhanced Vulnerability Repair FrameworkProceedings of the Association for Computational Linguistics, 2026
Semantics-Aligned, Curriculum-Driven, and Reasoning-Enhanced Vulnerability Repair FrameworkProceedings of the Association for Computational Linguistics, 2026 - EACL
 Pro-QuEST: Prompt-chaining Quiz Engine for testing Specialized Technical Product KnowledgeProceedings of the European Chapter of the Association for Computational Linguistics, 2026
Pro-QuEST: Prompt-chaining Quiz Engine for testing Specialized Technical Product KnowledgeProceedings of the European Chapter of the Association for Computational Linguistics, 2026 - AMIYA
 Improving Arabic Dialectness in LLMs with Reinforcement LearningAMIYA Workshop, 2026
Improving Arabic Dialectness in LLMs with Reinforcement LearningAMIYA Workshop, 2026





- ACL
 CodeArena: A collective evaluation platform for LLM code generationProceedings of the Association for Computational Linguistics, 2025
CodeArena: A collective evaluation platform for LLM code generationProceedings of the Association for Computational Linguistics, 2025 - ACL
 AntiLeakBench: Preventing Data Contamination by Automatically Constructing Benchmarks with Updated Real-World KnowledgeProceedings of the Association for Computational Linguistics, 2025
AntiLeakBench: Preventing Data Contamination by Automatically Constructing Benchmarks with Updated Real-World KnowledgeProceedings of the Association for Computational Linguistics, 2025 - AAAI
 Towards Verifiable Text Generation with Generative AgentProceedings of the AAAI Conference on Artificial Intelligence, 2025
Towards Verifiable Text Generation with Generative AgentProceedings of the AAAI Conference on Artificial Intelligence, 2025 - R2-FM@ICML
- PRAL@ICML
 Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency OptimizationPRAL Workshop at ICML 2025, 2025
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency OptimizationPRAL Workshop at ICML 2025, 2025 - JMIR
 Unraveling Online Mental Health Through the Lens of Early Maladaptive Schemas: AI-Enabled Content Analysis of Online Mental Health CommunitiesJournal of Medical Internet Research, 2025
Unraveling Online Mental Health Through the Lens of Early Maladaptive Schemas: AI-Enabled Content Analysis of Online Mental Health CommunitiesJournal of Medical Internet Research, 2025 - NeurIPS
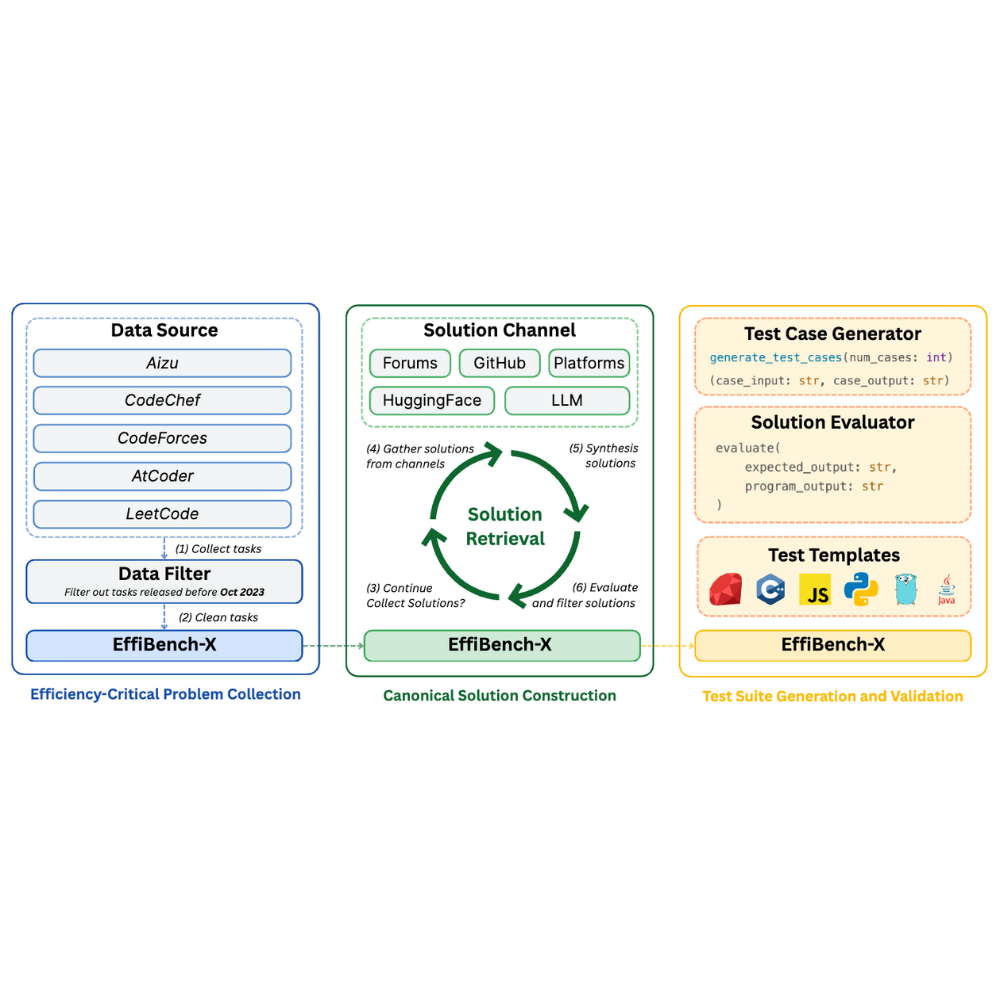 EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated CodeConference on Neural Information Processing Systems, 2025
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated CodeConference on Neural Information Processing Systems, 2025 - ICSE
 Measuring the Influence of Incorrect Code on Test Generationthe International Conference on Software Engineering, 2025
Measuring the Influence of Incorrect Code on Test Generationthe International Conference on Software Engineering, 2025 - NeurIPS Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency OptimizationConference on Neural Information Processing Systems, 2025
- NeurIPS Guardreasoner-VL: Safeguarding VLMs via Reinforced ReasoningConference on Neural Information Processing Systems, 2025
- EMNLP
 On Assigning Product and Software Codes to Service Requests with Large Language ModelsProceedings of the Conference on Empirical Methods in Natural Language Processing, 2025
On Assigning Product and Software Codes to Service Requests with Large Language ModelsProceedings of the Conference on Empirical Methods in Natural Language Processing, 2025 - ICML
 Position: Current Model Licensing Practices are Dragging Us into a Quagmire of Legal NoncomplianceInternational Conference on Machine Learning, 2025
Position: Current Model Licensing Practices are Dragging Us into a Quagmire of Legal NoncomplianceInternational Conference on Machine Learning, 2025 - SAC
 Curriculum Demonstration Selection for In-Context LearningACM/SIGAPP Symposium On Applied Computing, 2025
Curriculum Demonstration Selection for In-Context LearningACM/SIGAPP Symposium On Applied Computing, 2025











- AAAI
 Chain-of-Thought Improves Text Generation with Citations in Large Language ModelsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Chain-of-Thought Improves Text Generation with Citations in Large Language ModelsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024




- TLDK
 Constituency-Informed and Constituency-Constrained Extractive Question Answering with Heterogeneous Graph TransformerIn Transactions on Large-Scale Data-and Knowledge-Centered Systems LIII, 2023
Constituency-Informed and Constituency-Constrained Extractive Question Answering with Heterogeneous Graph TransformerIn Transactions on Large-Scale Data-and Knowledge-Centered Systems LIII, 2023 - WWW
 Identifying Checkworthy Cure Claims on TwitterIn Proceedings of the ACM Web Conference 2023, 2023
Identifying Checkworthy Cure Claims on TwitterIn Proceedings of the ACM Web Conference 2023, 2023



- CLEF
 NUS-IDS at CheckThat! 2022: identifying check-worthiness of tweets using CheckthaT5Working Notes of CLEF, 2022
NUS-IDS at CheckThat! 2022: identifying check-worthiness of tweets using CheckthaT5Working Notes of CLEF, 2022
